My amazing collaborators will be presenting three papers at EMNLP 2024 (main track), a leading conference in natural language processing, happening in Miami later this month! A few weeks ago I also blogged about our ACL 2024, ICML 2024, and CoLM 2024 papers – you can check the post here.
Our work at EMNLP 2024
We will be presenting three papers this year at EMNLP, a flagship NLP conference:
- A Simple and Effective $L_{2}$ Norm-Based Strategy for KV Cache Compression, by Yu Zhao, Alessio Devoto, et al. – we introduce a simple strategy for compressing the Key-Value (KV) cache in large language models by utilizing the $L_{2}$ norm of key embeddings; specifically, we found a correlation between low $L_{2}$ norms and high attention scores, allowing them to identify influential KV pairs before querying.
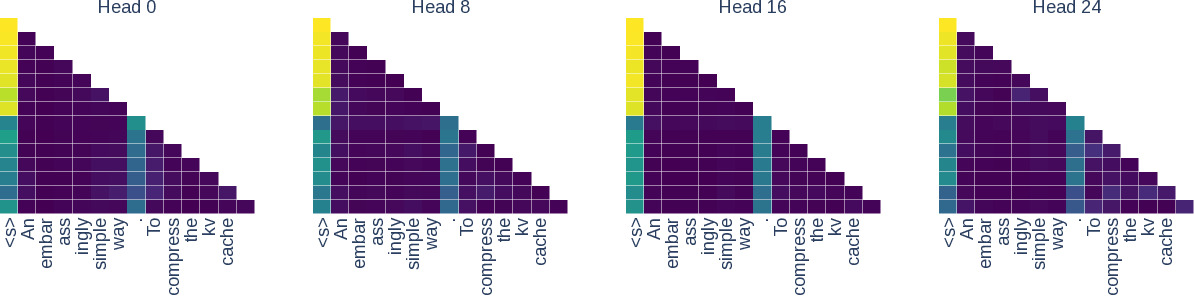
 For example, here we can see the attention distributions for five heads at layer 9 in Llama2-7B – we can see that the attention scores (top) and the key $L_{2}$ norms (bottom) are highly correlated. —
Our method effectively reduces KV cache size by up to 90% without loss of accuracy and is compatible with FlashAttention. This paper will be presented as an Oral – top 8% of the accepted papers! An extended version of this paper will also be presented at the Efficient Natural Language and Speech Processing workshop at NeurIPS 2024! EMNLP Poster
For example, here we can see the attention distributions for five heads at layer 9 in Llama2-7B – we can see that the attention scores (top) and the key $L_{2}$ norms (bottom) are highly correlated. —
Our method effectively reduces KV cache size by up to 90% without loss of accuracy and is compatible with FlashAttention. This paper will be presented as an Oral – top 8% of the accepted papers! An extended version of this paper will also be presented at the Efficient Natural Language and Speech Processing workshop at NeurIPS 2024! EMNLP Poster - Atomic Inference for NLI with Generated Facts as Atoms, by Joe Stacey et al. – we propose an atomic inference approach for Natural Language Inference (NLI) that decomposes inputs into individual facts or atoms, and explicitly models the entailment relationships between such atoms. Furthermore, we propose a multi-stage fact generation process and a specialized training regime for incorporates such facts, achieving state-of-the-art results in several hard NLI tasks. Our best system, FGLR, produces significantly more robust and accurate results than large-scale language models while providing clear interpretability guarantees by identifying the specific atoms responsible for each prediction! Joe wrote an amazing blog post on this work, check it out!
- Unveiling and Consulting Core Experts in Retrieval-Augmented MoE-based LLMs, by Xin Zhou, Ping Nie et al. – we analyse Mixture-of-Expert (MoE)-based Large Language Models (LLMs) in the context of Retrieval-Augmented Generation (RAG); we identify the groups of experts that are primarily responsible for RAG-related behaviors, such as identifying whether the parametric knowledge is sufficient to solve a given knowledge-intensive task; assessing the quality of retrieved documents; and improving the utilisation of context. Based on these findings, we propose several strategies to improve the efficiency and effectiveness of RAG systems by adjusting expert activations.
What’s brewing
We have several super-interesting works in the pipeline! Here are some of them:
- Steering Knowledge Selection Behaviours in LLMs via SAE-Based Representation Engineering, by Yu Zhao et al. – we introduce SpARE, a training-free method that leverages pre-trained sparse auto-encoders (SAEs) to control the knowledge selection behavior of large language models (LLMs) when faced with conflicts between their internal (parametric) knowledge and external (contextual) information. By identifying and manipulating functional features within the LLMs’ internal activations, SpARE can steer the model to prioritize either parametric or contextual knowledge during inference. We show that SpARE is surprisingly effective at resolving knowledge conflicts in open-domain question-answering tasks, producing significantly better results than existing representation engineering and contrastive decoding methods. The insights in this paper are based on another paper, Analysing the Residual Stream of Language Models Under Knowledge Conflicts also by Yu Zhao et al. that will appear in the Workshop on Foundation Model Interventions @ NeurIPS 2024.
- Mixtures of In-Context Learners, by Giwon Hong et al. – we propose Mixtures of In-Context Learners (MoICL), a method that trains a set of experts via in-context learning, and learns a weighting function to merge their outputs, addressing many of the limitations of standard in-context learning (ICL). MoICL yields significantly more accurate results than many strong baselines (up to +13% compared to ICL and LENS); reduces inference time by achieving similar performance with fewer demonstrations; and shows greater robustness to out-of-domain, imbalanced, or noisy demonstrations.
- DeCoRe: Decoding by Contrasting Retrieval Heads to Mitigate Hallucinations, by Aryo Gema et al. – we introduce DeCoRe (Decoding by Contrasting Retrieval Heads), a novel, training-free decoding strategy designed to mitigate hallucinations in large language models (LLMs). DeCoRe works by masking specific retrieval heads — attention heads responsible for extracting relevant contextual information — to induce hallucinations, and then contrast the outputs of the base LLM and the masked LLM, using conditional entropy as a guide. DeCoRe significantly improves performance on tasks requiring high contextual faithfulness, such as summarization, instruction following, and open-book question answering, and surprisingly (to us), it also helps with factual recall!
- FLARE: Faithful Logic-Aided Reasoning and Exploration, by Erik Arakelyan et al. – we introduce FLARE (Faithful Logic-Aided Reasoning and Exploration), a framework designed to improve the reasoning abilities of LLMs in knowledge-intensive reasoning tasks. FLARE use an intermediate logic programming-inspired representation of the reasoning process by generating Prolog code and simulating a program execution, ensuring that the reasoning process remains faithful and interpretable without relying on external solvers. FLARE achieves state-of-the-art results on seven out of nine diverse reasoning benchmarks, and we identify a strong correlation between the faithfulness of the reasoning process and the downstream model accuracy.